학습 목표
이번 강의에서는 여러분이 보유한 데이터를 기반으로 실시간 질의응답이 가능한 RAG(Retrieval Augmented Generation) 봇을 파이썬으로 직접 구현하는 방법을 학습합니다. 단순히 이론에 그치지 않고, OpenAI의 최신 API와 LangChain 프레임워크를 활용하여 실제 작동하는 봇을 만드는 실전 경험을 제공하는 것이 목표입니다. 이 강의를 통해 다음을 달성할 수 있습니다:
- RAG(Retrieval Augmented Generation) 아키텍처의 핵심 원리와 필요성을 이해합니다.
- OpenAI API를 활용하여 텍스트 임베딩(Embedding)을 생성하고, 이를 벡터 데이터베이스에 저장하는 방법을 익힙니다.
- LangChain 라이브러리를 사용하여 데이터 로딩, 텍스트 분할, 임베딩, 벡터 검색, 그리고 LLM(Large Language Model) 연동까지의 전체 RAG 파이프라인을 구축합니다.
- 사용자 정의 데이터에 기반한 정확하고 신뢰할 수 있는 답변을 제공하는 실시간 질의응답 봇을 구현합니다.
- 향후 여러분의 서비스에 RAG 기술을 적용하기 위한 견고한 기초를 다집니다.
사전 준비 사항
본 실습을 원활하게 진행하기 위해 다음 개발 환경 및 필수 라이브러리들을 미리 준비해 주시기 바랍니다.
권장 개발 환경
- 통합 개발 환경 (IDE): Visual Studio Code (최신 버전 권장)
- 운영체제 (OS): Windows 10/11, macOS (Sonoma 이상), Linux (Ubuntu 22.04 LTS 이상)
- 파이썬 (Python) 버전: 3.9 ~ 3.11 버전 (안정적인 실습을 위해 Python 3.10 버전을 권장합니다.)
필수 라이브러리 설치
프로젝트 폴더를 생성한 후, 터미널 또는 명령 프롬프트를 열어 다음 명령어를 실행하여 필요한 라이브러리들을 한 번에 설치합니다. 가상 환경을 활성화한 후 설치하는 것을 강력히 권장합니다.
# 가상 환경 생성 (선택 사항이지만 권장)
python -m venv venv
# 가상 환경 활성화
# Windows
.\venv\Scripts\activate
# macOS/Linux
source venv/bin/activate
# 필수 라이브러리 설치
pip install openai langchain faiss-cpu pypdf tiktoken python-dotenv
각 라이브러리의 역할은 다음과 같습니다:
openai: ChatGPT API (LLM 및 임베딩)와의 통신을 담당합니다.langchain: RAG 파이프라인 구축을 위한 핵심 프레임워크입니다. 데이터 로딩, 분할, 임베딩, 검색, LLM 연동 등 다양한 기능을 제공합니다.faiss-cpu: 벡터 데이터베이스 역할을 하며, 벡터 검색의 효율성을 높여줍니다. (CPU 버전)pypdf: PDF 문서를 로드하고 텍스트를 추출하는 데 사용됩니다.tiktoken: OpenAI 모델의 토큰화를 관리하고, 토큰 수를 계산하는 데 유용합니다.python-dotenv: API 키와 같은 민감한 정보를 환경 변수로 안전하게 관리할 수 있도록 돕습니다.
OpenAI API 키 발급 및 설정
OpenAI 플랫폼(platform.openai.com/account/api-keys)에서 API 키를 발급받아야 합니다. 발급받은 키는 보안을 위해 프로젝트 폴더 내 .env 파일에 다음과 같이 저장합니다.
OPENAI_API_KEY="여러분의_발급받은_API_키를_여기에_입력하세요"
이 키는 강의 전체에서 ChatGPT 및 임베딩 모델에 접근하는 데 사용됩니다. 절대로 이 키를 공개 저장소에 업로드하지 않도록 주의하십시오.
단계별 실습 과정
이제 본격적으로 RAG 봇을 구축하는 실습을 시작하겠습니다. 각 단계를 차근차근 따라오시면 여러분만의 질의응답 봇을 완성할 수 있습니다.
1단계: 프로젝트 초기 설정 및 환경 변수 관리
먼저 프로젝트 폴더를 생성하고, 필요한 파일들을 구성합니다. 터미널에서 다음 명령어를 실행합니다.
mkdir my_rag_bot
cd my_rag_bot
touch main.py .env data.pdf
data.pdf 파일은 여러분이 질의응답 봇에 활용할 실제 데이터 문서입니다. 임의의 PDF 문서를 이 폴더에 복사해 두십시오. (예: 회사 소개서, 제품 매뉴얼, FAQ 문서 등)
.env 파일에는 위에서 설명한 OpenAI API 키를 저장합니다.
OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
main.py 파일에 다음 코드를 추가하여 환경 변수를 로드할 준비를 합니다.
# main.py
import os
from dotenv import load_dotenv
# .env 파일에서 환경 변수 로드
load_dotenv()
# OpenAI API 키 가져오기
openai_api_key = os.getenv("OPENAI_API_KEY")
# 키가 제대로 로드되었는지 확인 (선택 사항)
if not openai_api_key:
raise ValueError("OPENAI_API_KEY 환경 변수가 설정되지 않았습니다.")
else:
print("OpenAI API 키가 성공적으로 로드되었습니다.")
python main.py를 실행하여 “OpenAI API 키가 성공적으로 로드되었습니다.” 메시지가 출력되면 성공입니다.

이 단계에서는 프로젝트의 기본 구조를 설정하고, 보안상 중요한 API 키를 안전하게 관리하는 방법을 익혔습니다. 이는 모든 AI 프로젝트의 기본 중 기본입니다.
2단계: 데이터 로딩 및 전처리
이제 질의응답에 사용할 여러분의 데이터를 로드하고, LLM이 처리하기 적합한 형태로 전처리하는 과정을 진행합니다. PDF 문서를 예시로 사용하겠습니다.
# main.py (이전 코드에 이어서 추가)
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 1. 데이터 로드
# 프로젝트 폴더 내의 data.pdf 파일을 로드합니다.
# 실제 사용 시에는 여러 파일을 로드하거나 다른 형식의 데이터를 사용할 수 있습니다.
data_path = "data.pdf"
print(f"\n1. {data_path} 파일 로딩 중...")
loader = PyPDFLoader(data_path)
documents = loader.load()
print(f" - {len(documents)} 페이지 로드 완료.")
# 2. 텍스트 분할 (청크 생성)
# LLM의 컨텍스트 윈도우 한계를 고려하여 문서를 적절한 크기로 분할합니다.
# RecursiveCharacterTextSplitter는 다양한 구분자를 사용하여 효과적으로 분할합니다.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 각 청크의 최대 문자 수
chunk_overlap=200, # 청크 간 중복되는 문자 수 (문맥 유지를 위함)
length_function=len,
add_start_index=True,
)
texts = text_splitter.split_documents(documents)
print(f"2. {len(texts)}개의 텍스트 청크 생성 완료.")
print(f" - 첫 번째 청크 미리보기: {texts[0].page_content[:200]}...")
이 코드는 data.pdf 파일을 페이지별로 로드한 다음, 각 페이지의 텍스트를 1000자 단위로 분할합니다. 이때 200자의 오버랩을 두어 한 청크의 끝 내용과 다음 청크의 시작 내용이 중복되도록 하여 문맥 손실을 최소화합니다. 이렇게 분할된 텍스트 청크들이 LLM에 전달될 검색 대상이 됩니다.
3단계: 임베딩 생성 및 벡터 데이터베이스 구축
분할된 텍스트 청크들을 숫자의 벡터(임베딩)로 변환하고, 이 벡터들을 효율적으로 검색할 수 있는 벡터 데이터베이스를 구축합니다. 여기서는 FAISS를 사용합니다.
# main.py (이전 코드에 이어서 추가)
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# 3. 임베딩 생성 및 벡터 데이터베이스 구축
print("\n3. 텍스트 청크 임베딩 및 FAISS 벡터 저장소 구축 중...")
# OpenAIEmbeddings 모델을 사용하여 텍스트를 벡터로 변환합니다.
# API 키는 load_dotenv()로 이미 설정되어 있으므로 별도 인자 불필요.
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# FAISS.from_documents()를 사용하여 문서 청크와 임베딩 모델로 벡터 저장소를 생성합니다.
# 이 과정은 청크 수에 따라 시간이 다소 소요될 수 있습니다.
vectorstore = FAISS.from_documents(texts, embeddings)
# 생성된 벡터 저장소를 로컬에 저장하여 다음 실행 시 재사용할 수 있도록 합니다.
# 실제 서비스에서는 이 파일을 캐싱하거나 영구 저장소에 보관합니다.
vectorstore.save_local("faiss_index")
print(" - FAISS 벡터 저장소 'faiss_index'에 저장 완료.")
OpenAIEmbeddings는 각 텍스트 청크를 고차원 벡터 공간의 점으로 변환합니다. 이 벡터들은 텍스트의 의미를 숫자로 표현한 것이며, 의미적으로 유사한 텍스트는 벡터 공간에서도 서로 가까이 위치하게 됩니다. FAISS는 이렇게 생성된 벡터들을 저장하고, 주어진 질의 벡터와 가장 유사한(가까운) 문서 벡터들을 빠르게 찾아내는 역할을 합니다.
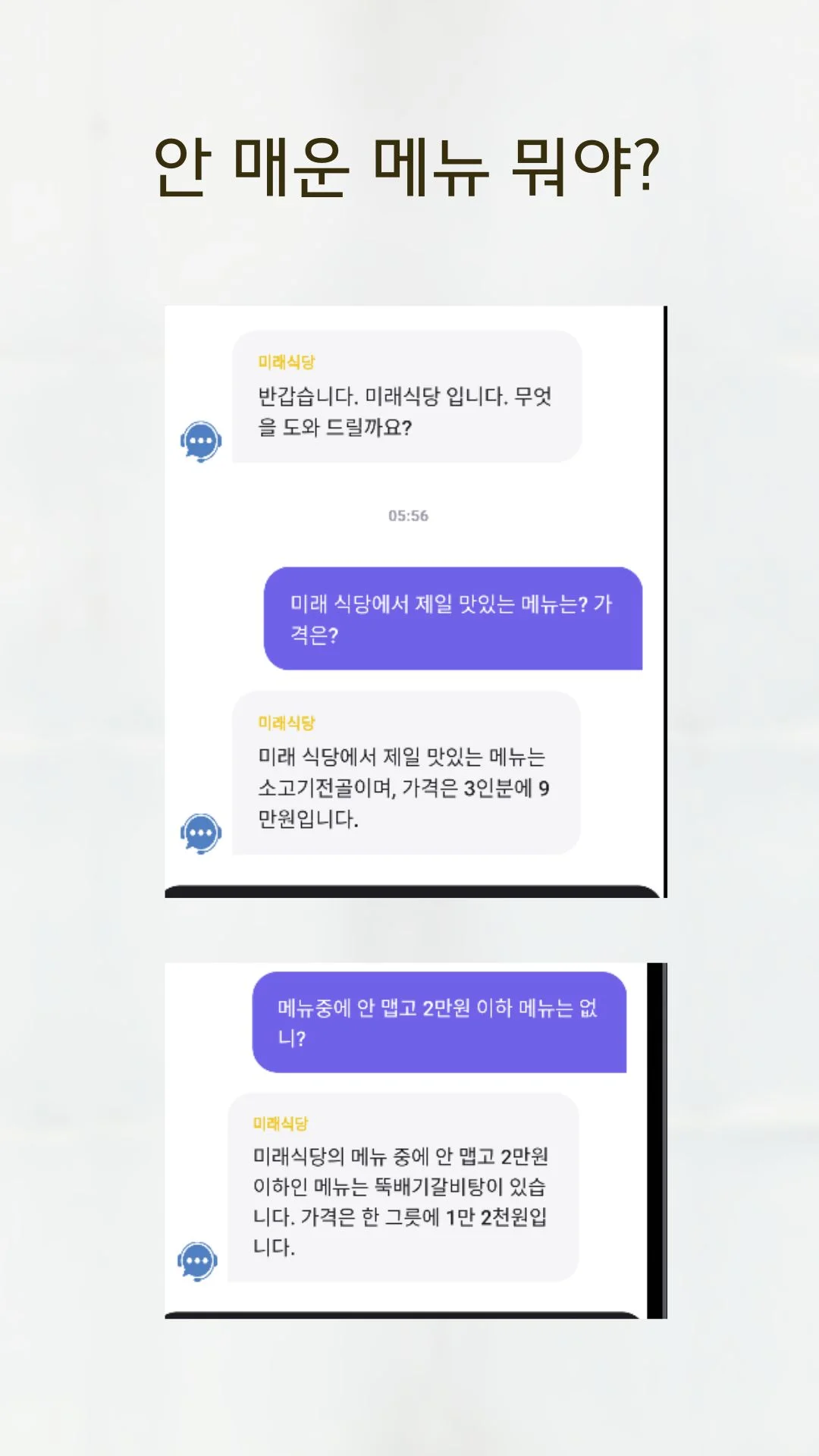
이 과정을 통해 우리는 여러분의 데이터를 LLM이 이해하고 검색할 수 있는 형태로 변환하고, 검색 효율성을 극대화하는 기반을 마련했습니다.
4단계: RAG 질의응답 체인 구현
이제 사용자의 질문에 답변을 생성하기 위한 RAG 체인을 구축합니다. 이는 사용자의 질문에 가장 관련성 높은 문서를 검색하고, 이 문서를 기반으로 LLM이 답변을 생성하도록 지시하는 과정입니다.
# main.py (이전 코드에 이어서 추가)
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# 4. RAG 질의응답 체인 구현
print("\n4. RAG 질의응답 체인 설정 중...")
# 이전에 저장했던 FAISS 벡터 저장소를 로드합니다.
# 매번 임베딩을 다시 생성할 필요 없이 저장된 인덱스를 활용합니다.
loaded_vectorstore = FAISS.load_local("faiss_index", embeddings, allow_dangerous_deserialization=True)
# LLM 모델 초기화 (ChatGPT 3.5 Turbo 사용)
# temperature는 0으로 설정하여 답변의 일관성을 높입니다.
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# RetrievalQA 체인 설정
# retriever: 벡터 저장소에서 관련 문서를 검색하는 역할을 합니다.
# k=3은 가장 유사한 문서 3개를 가져오겠다는 의미입니다.
# llm: 검색된 문서를 바탕으로 답변을 생성할 LLM입니다.
# return_source_documents=True: 답변과 함께 출처 문서도 반환하도록 설정합니다.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 'stuff'는 모든 문서를 하나의 프롬프트로 합쳐 LLM에 전달합니다.
retriever=loaded_vectorstore.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True
)
print(" - RAG 질의응답 체인 설정 완료.")
이 단계에서는 이전에 생성한 FAISS 인덱스를 로드하고, 이를 retriever로 활용합니다. ChatOpenAI를 통해 ChatGPT 모델을 연결하고, RetrievalQA 체인을 구성하여 사용자의 질문이 들어왔을 때 자동으로 다음 과정을 수행하도록 합니다:
- 사용자 질문을 임베딩합니다.
- 임베딩된 질문으로 FAISS 벡터 데이터베이스에서 가장 유사한 상위
k개의 문서를 검색합니다. - 검색된 문서들과 사용자 질문을 조합하여 LLM에 프롬프트로 전달합니다.
- LLM은 이 정보를 바탕으로 가장 적절한 답변을 생성하여 반환합니다.
5단계: 실시간 질의응답 봇 인터페이스 구축
이제 사용자와 상호작용할 수 있는 간단한 콘솔 기반의 인터페이스를 만듭니다. 사용자가 질문을 입력하면, RAG 체인을 통해 답변을 받아 출력하는 루프를 구현합니다.
# main.py (이전 코드에 이어서 추가)
# 5. 실시간 질의응답 봇 인터페이스 구축
print("\n5. 실시간 질의응답 봇 실행 중... (종료: 'exit' 또는 'quit')")
while True:
query = input("\n질문하세요: ")
if query.lower() in ["exit", "quit"]:
print("봇을 종료합니다.")
break
if query.strip() == "":
print("질문을 입력해주세요.")
continue
try:
# RAG 체인 호출하여 답변 및 출처 문서 가져오기
result = qa_chain({"query": query})
answer = result["result"]
source_documents = result["source_documents"]
print(f"\n[답변]: {answer}")
# 출처 문서 정보 출력
if source_documents:
print("\n[참고 문서]:")
for i, doc in enumerate(source_documents):
print(f" - 문서 {i+1}: {doc.metadata.get('source', '알 수 없음')}, 페이지 {doc.metadata.get('page', '알 수 없음')}")
# print(f" 내용 일부: {doc.page_content[:100]}...") # 디버깅용
else:
print(" (관련 문서를 찾을 수 없습니다.)")
except Exception as e:
print(f"오류 발생: {e}")
print("API 키가 유효한지, 인터넷 연결이 잘 되어 있는지 확인해주세요.")
이 코드는 무한 루프를 통해 사용자로부터 질문을 입력받고, 입력된 질문을 qa_chain에 전달하여 답변을 받아옵니다. 답변과 함께 LLM이 답변 생성에 참고한 출처 문서의 정보(원본 파일명, 페이지 번호 등)도 함께 출력하여 답변의 신뢰성을 높입니다. 사용자가 ‘exit’ 또는 ‘quit’을 입력하면 봇이 종료됩니다.

결과 확인
모든 코드를 작성하고 main.py를 저장했다면, 터미널에서 다음 명령어를 실행하여 여러분의 RAG 질의응답 봇을 시작할 수 있습니다.
# 가상 환경이 활성화된 상태에서 실행
python main.py
봇이 시작되면 “질문하세요: ” 프롬프트가 나타날 것입니다. data.pdf 파일에 있는 내용과 관련된 질문을 입력해보세요. 예를 들어, data.pdf가 회사 소개서라면 “우리 회사의 주요 제품은 무엇인가요?”와 같은 질문을 할 수 있습니다.
예상되는 결과 시나리오:
- 정확한 답변:
data.pdf내에 명확한 정보가 있다면, LLM은 해당 정보를 바탕으로 정확하고 간결한 답변을 생성할 것입니다. 답변과 함께 어떤 문서의 몇 페이지에서 해당 정보를 찾았는지 출처도 함께 표시됩니다. - 정보 부재 시: 만약 질문에 대한 정보가
data.pdf내에 없다면, LLM은 “해당 정보는 문서에서 찾을 수 없습니다”와 유사한 답변을 하거나, 일반적인 지식으로 답변하되 출처 문서가 없음을 명시할 수 있습니다. (이는 LLM의 설정과 질문의 모호성에 따라 달라질 수 있습니다.) - 오류 발생 시: API 키가 잘못되었거나, 인터넷 연결이 불안정하거나, PDF 파일 경로가 잘못된 경우 오류 메시지가 출력될 수 있습니다. 이 경우 터미널의 오류 메시지를 확인하고 조치해야 합니다.
이 튜토리얼을 통해 여러분은 여러분의 데이터를 기반으로 작동하는 강력한 RAG 질의응답 봇을 성공적으로 구축했습니다. 이는 단순한 챗봇을 넘어, 특정 지식 기반에 특화된 AI 어시스턴트를 만드는 첫걸음입니다. 이 기술은 고객 지원, 사내 지식 관리, 교육 등 무궁무진한 분야에 적용될 수 있습니다.
더 나아가, FAISS 대신 ChromaDB나 Pinecone과 같은 클라우드 기반 벡터 데이터베이스를 사용하거나, Streamlit, Gradio와 같은 UI 프레임워크를 활용하여 웹 기반 인터페이스를 구축하는 등 다양한 방식으로 확장할 수 있습니다. 실습을 통해 얻은 지식과 경험을 바탕으로 여러분의 아이디어를 현실로 만들어나가시길 바랍니다.