학습 목표
본 강의는 2026년 현재, 웹 개발 환경에서 필수적인 동적 콘텐츠 처리를 위해 Playwright와 Python을 활용하여 무한 스크롤 웹사이트의 데이터를 효율적으로 크롤링하는 실질적인 기술을 습득하는 것을 목표로 합니다. 여러분은 이 실습을 통해 단순히 데이터를 추출하는 것을 넘어, 웹 페이지의 동적 로딩 메커니즘을 이해하고, Playwright의 강력한 비동기 기능을 활용하여 실제 운영 환경에서 발생할 수 있는 다양한 웹 크롤링 시나리오에 대처할 수 있는 역량을 갖추게 될 것입니다. 특히, 무한 스크롤 웹사이트의 특성을 파악하고, 페이지 하단으로 스크롤하여 새로운 콘텐츠를 로드하는 과정을 자동화하며, 로드된 모든 데이터를 안정적으로 수집하여 구조화된 형태로 저장하는 방법을 완벽하게 마스터하게 될 것입니다.
사전 준비 사항
본 실습을 성공적으로 수행하기 위한 필수적인 개발 환경 및 라이브러리 설치 정보를 안내합니다. 원활한 학습 경험을 위해 아래 지침을 따라 환경을 설정해 주시기 바랍니다.
권장 개발 환경
- 운영체제(OS): Windows 10/11, macOS (Ventura 이상), Linux (Ubuntu 22.04 LTS 이상)
- 통합 개발 환경(IDE): Visual Studio Code (최신 버전 권장)
- Python 버전: 3.9 이상 (본 실습은 Python 3.11 환경에서 테스트되었으며, 최신 버전일수록 좋습니다.)
필수 라이브러리 설치
Playwright와 데이터 처리를 위한 라이브러리들을 설치합니다. 터미널 또는 명령 프롬프트를 열고 다음 명령어를 순서대로 실행하세요.
# Playwright 및 브라우저 드라이버 설치
pip install playwright
playwright install
# HTML 파싱 및 데이터 처리를 위한 라이브러리 설치
pip install beautifulsoup4 pandas
playwright install 명령은 Chromium, Firefox, WebKit 등 Playwright가 지원하는 모든 브라우저의 실행 파일을 자동으로 다운로드하여 설정합니다. 이 과정은 인터넷 연결 상태에 따라 다소 시간이 소요될 수 있습니다.
단계별 실습 과정
이제 본격적으로 Playwright와 Python을 활용하여 무한 스크롤 웹사이트에서 데이터를 크롤링하는 과정을 단계별로 실습해 보겠습니다. 본 강의에서는 가상의 무한 스크롤 뉴스 피드 웹사이트(예: https://example.com/infinite-news)를 대상으로 진행한다고 가정합니다. 실제 웹사이트에 적용 시 해당 웹사이트의 정책을 준수해야 함을 명심하십시오.
1단계: Playwright 설치 및 초기 설정
이전 단계에서 이미 설치를 완료했지만, 실습을 위한 기본적인 Python 스크립트 구조를 설정하고 Playwright를 초기화하는 과정을 다시 한번 확인합니다. 새로운 Python 파일(예: infinite_scroll_crawler.py)을 생성하고 다음 코드를 작성합니다.
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# 브라우저 실행 (headless=True는 백그라운드 실행, 개발 시에는 False로 설정하여 GUI 확인 가능)
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# 대상 웹사이트 URL 설정
target_url = "https://example.com/infinite-news" # 실제 무한 스크롤 웹사이트 URL로 변경하세요.
await page.goto(target_url, wait_until="networkidle") # 네트워크가 안정화될 때까지 대기
print(f"'{target_url}' 페이지 로드 완료.")
# TODO: 여기에 무한 스크롤 및 데이터 추출 로직 추가
await browser.close()
if __name__ == "__main__":
asyncio.run(main())
이 코드는 Playwright를 사용하여 Chromium 브라우저를 실행하고, 지정된 URL로 이동하는 기본 골격을 제공합니다. wait_until="networkidle" 옵션은 페이지의 모든 네트워크 요청이 일정 시간 동안 없을 때까지 기다리므로, 초기 페이지 로딩을 안정적으로 처리하는 데 유용합니다.
2단계: 비동기 웹 페이지 접근 및 초기 로드
웹 페이지에 접근한 후, 초기 로드된 콘텐츠를 확인하는 것이 중요합니다. 무한 스크롤 웹사이트는 일반적으로 초기 로드 시 일부 데이터만 표시하고, 스크롤을 내리면 추가 데이터를 로드합니다. 우리는 첫 단계에서 페이지에 성공적으로 접속했는지 확인하고, 초기 데이터를 파악하는 데 집중할 것입니다.
# ... (이전 코드 생략)
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False) # 개발 단계에서는 GUI를 보는 것이 좋습니다.
page = await browser.new_page()
target_url = "https://example.com/infinite-news"
await page.goto(target_url, wait_until="networkidle")
print(f"'{target_url}' 페이지 로드 완료.")
# 초기 로드된 기사 개수 확인 (예: 기사 아이템이 article 태그에 있다고 가정)
initial_articles = await page.locator("article.news-item").count()
print(f"초기 로드된 기사 개수: {initial_articles}개")
# TODO: 여기에 무한 스크롤 및 데이터 추출 로직 추가
await browser.close()
# ... (이후 코드 생략)
page.locator("article.news-item").count()는 CSS 셀렉터 article.news-item에 해당하는 요소의 개수를 반환합니다. 이 코드를 통해 초기 페이지에 몇 개의 기사 아이템이 로드되었는지 확인할 수 있습니다. 이 정보는 이후 무한 스크롤 시 새로운 콘텐츠가 로드되었는지 판단하는 기준이 될 수 있습니다.
3단계: 무한 스크롤 구현 전략
무한 스크롤 웹사이트의 핵심은 페이지 하단으로 스크롤하여 더 많은 콘텐츠를 로드하는 것입니다. 이를 위해 Playwright의 page.evaluate() 메서드를 사용하여 JavaScript 코드를 실행하고, 스크롤 후 새로운 콘텐츠가 로드될 때까지 기다리는 전략을 사용합니다.
# ... (이전 코드 생략)
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
target_url = "https://example.com/infinite-news"
await page.goto(target_url, wait_until="networkidle")
print(f"'{target_url}' 페이지 로드 완료.")
all_articles_data = []
previous_article_count = 0
scroll_count = 0
max_scrolls = 5 # 최대 스크롤 횟수 설정 (무한 루프 방지)
while scroll_count < max_scrolls:
# 현재 스크롤 높이 확인
current_scroll_height = await page.evaluate("document.body.scrollHeight")
# 페이지 하단으로 스크롤
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# 새로운 콘텐츠가 로드될 때까지 대기 (네트워크 활동 대기 또는 특정 요소 출현 대기)
# 여기서는 0.5초 대기 후, 다음 스크롤 위치가 변경되었는지 확인하는 방식으로 진행합니다.
# 실제 환경에서는 'networkidle' 또는 특정 로딩 스피너가 사라질 때까지 기다리는 것이 더 안정적입니다.
await page.wait_for_timeout(500) # 0.5초 대기
# 스크롤 후 새로운 기사 개수 확인
current_article_count = await page.locator("article.news-item").count()
print(f"스크롤 {scroll_count+1}회 후, 현재 기사 개수: {current_article_count}개")
if current_article_count == previous_article_count:
print("더 이상 새로운 기사가 로드되지 않습니다. 스크롤 중단.")
break # 더 이상 새로운 기사가 없으면 루프 종료
previous_article_count = current_article_count
scroll_count += 1
print(f"총 {scroll_count}회 스크롤 완료.")
# TODO: 데이터 추출 로직 추가
await browser.close()
if __name__ == "__main__":
asyncio.run(main())
위 코드는 max_scrolls 횟수만큼 반복하며 페이지를 스크롤합니다. window.scrollTo(0, document.body.scrollHeight)는 페이지를 가장 아래로 스크롤하는 JavaScript 코드입니다. 스크롤 후에는 page.wait_for_timeout()을 사용하여 잠시 대기하고, 로드된 기사의 개수가 이전과 동일하면 더 이상 로드할 콘텐츠가 없다고 판단하여 스크롤을 중단합니다. 실제 웹사이트에서는 로딩 인디케이터나 특정 요소의 출현 여부를 page.wait_for_selector() 등을 활용하여 기다리는 것이 더욱 견고한 방법입니다.
4단계: 데이터 추출 및 파싱
모든 콘텐츠가 로드되었다고 가정하고, 이제 페이지에서 원하는 데이터를 추출하고 파싱하는 단계입니다. 각 기사 아이템에서 제목, 작성자, 내용 요약 등의 정보를 추출해 보겠습니다. Playwright의 locator API를 사용하여 요소를 선택하고 텍스트를 추출하는 것이 가장 효율적입니다.
# ... (이전 코드 생략)
import pandas as pd
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True) # 추출 단계에서는 GUI가 필요 없을 수 있습니다.
page = await browser.new_page()
target_url = "https://example.com/infinite-news"
await page.goto(target_url, wait_until="networkidle")
# ... (무한 스크롤 로직 생략, 위 3단계 코드 포함)
print("데이터 추출 시작...")
all_articles_data = []
# 모든 기사 아이템 선택
article_elements = await page.locator("article.news-item").all()
for article_element in article_elements:
try:
title_element = article_element.locator("h2.article-title")
title = await title_element.text_content() if await title_element.count() > 0 else "N/A"
author_element = article_element.locator("span.article-author")
author = await author_element.text_content() if await author_element.count() > 0 else "N/A"
summary_element = article_element.locator("p.article-summary")
summary = await summary_element.text_content() if await summary_element.count() > 0 else "N/A"
# 링크 추출 예시
link_element = article_element.locator("a.article-link")
link = await link_element.get_attribute("href") if await link_element.count() > 0 else "N/A"
all_articles_data.append({
"title": title.strip(),
"author": author.strip(),
"summary": summary.strip(),
"link": link
})
except Exception as e:
print(f"기사 데이터 추출 중 오류 발생: {e}")
continue
print(f"총 {len(all_articles_data)}개의 기사 데이터 추출 완료.")
# TODO: 추출된 데이터 저장 로직 추가
await browser.close()
if __name__ == "__main__":
asyncio.run(main())
이 코드에서는 page.locator("article.news-item").all()을 사용하여 모든 기사 요소를 가져온 다음, 각 요소에 대해 다시 locator를 사용하여 제목, 작성자, 요약, 링크 등의 세부 정보를 추출합니다. text_content()는 요소의 텍스트 내용을 반환하며, get_attribute("href")는 링크의 href 속성 값을 가져옵니다. try-except 블록을 사용하여 특정 요소가 없는 경우에도 스크립트가 중단되지 않고 다음 기사로 넘어갈 수 있도록 처리합니다.
5단계: 추출된 데이터 저장
추출된 데이터를 효율적으로 관리하고 분석하기 위해 Pandas DataFrame으로 변환한 후, CSV 파일로 저장하는 것이 일반적입니다. CSV는 다양한 프로그램에서 쉽게 읽고 쓸 수 있는 표준 형식입니다.
# ... (이전 코드 생략)
import pandas as pd
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
target_url = "https://example.com/infinite-news"
await page.goto(target_url, wait_until="networkidle")
# ... (무한 스크롤 및 데이터 추출 로직 포함)
if all_articles_data:
df = pd.DataFrame(all_articles_data)
# CSV 파일로 저장 (인코딩을 utf-8-sig로 설정하여 엑셀에서 한글 깨짐 방지)
df.to_csv("infinite_news_data.csv", index=False, encoding="utf-8-sig")
print("데이터가 'infinite_news_data.csv' 파일로 성공적으로 저장되었습니다.")
else:
print("추출된 데이터가 없습니다.")
await browser.close()
if __name__ == "__main__":
asyncio.run(main())
pd.DataFrame(all_articles_data)는 리스트 형태의 딕셔너리 데이터를 Pandas DataFrame으로 변환합니다. df.to_csv("infinite_news_data.csv", index=False, encoding="utf-8-sig")는 이 DataFrame을 CSV 파일로 저장하며, index=False는 DataFrame의 인덱스를 파일에 저장하지 않도록 합니다. encoding="utf-8-sig"는 한글 데이터가 포함될 경우 Microsoft Excel 등에서 깨지지 않도록 하는 중요한 설정입니다.
결과 확인
모든 실습 과정을 마쳤다면, 이제 스크립트가 성공적으로 데이터를 추출하고 저장했는지 확인해야 합니다. 터미널에서 다음 명령어를 실행하여 Python 스크립트를 실행합니다.
python infinite_scroll_crawler.py
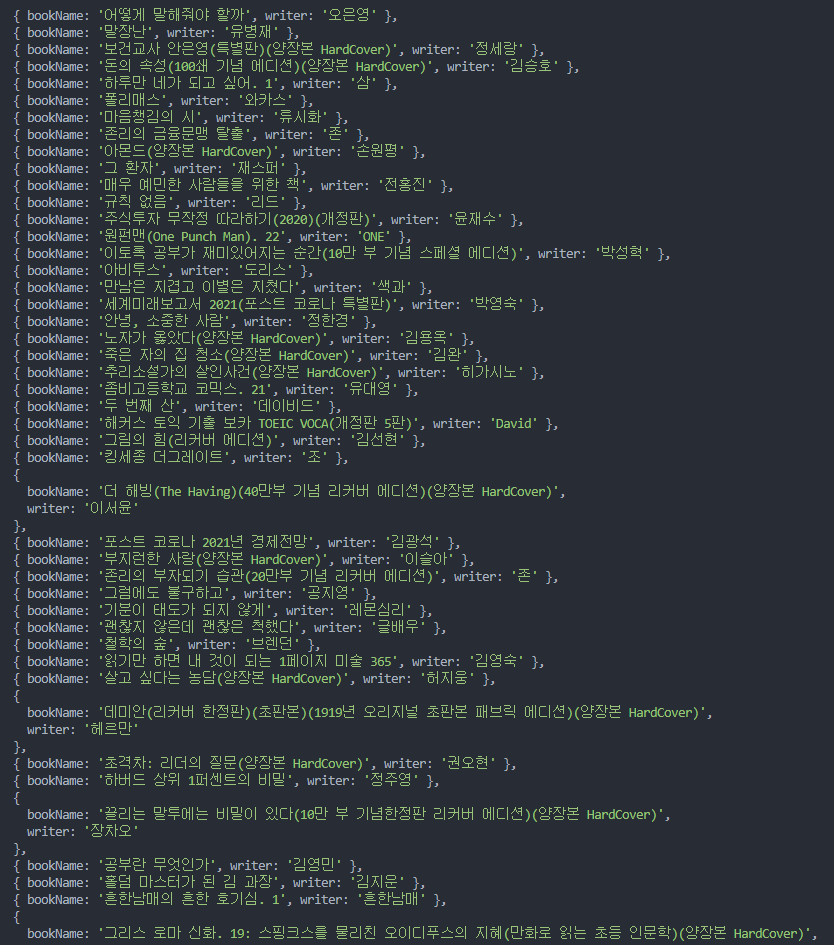
스크립트가 실행되면 브라우저가 열리고(headless=False인 경우), 페이지를 스크롤하며 데이터를 수집한 후, 최종적으로 infinite_news_data.csv 파일이 생성될 것입니다. 이 CSV 파일을 텍스트 에디터나 스프레드시트 프로그램(예: Excel, Google Sheets)으로 열어 추출된 데이터를 확인합니다.
파일을 열었을 때, 각 기사의 제목, 작성자, 요약, 링크 정보가 올바르게 구조화되어 있는지 확인합니다. 데이터의 누락이나 오류가 있는지 검토하여 스크립트의 정확성을 검증할 수 있습니다. 예를 들어, 추출된 기사의 수가 예상한 총 스크롤 횟수와 일치하는지, 각 필드에 의미 있는 값이 들어있는지 등을 확인하는 것이 중요합니다.
만약 데이터가 기대한 대로 추출되지 않았다면, 다음 사항들을 점검해 보세요:
- CSS 셀렉터 오류: 웹사이트의 HTML 구조가 변경되었거나, 셀렉터가 정확하지 않을 수 있습니다. 개발자 도구(F12)를 사용하여 올바른 셀렉터를 다시 확인하세요.
- 스크롤 로직 오류: 웹사이트마다 무한 스크롤 구현 방식이 다를 수 있습니다.
page.wait_for_timeout()대신page.wait_for_selector()나page.wait_for_load_state('networkidle')와 같은 더 견고한 대기 방식을 시도해 보세요. - Anti-bot 감지: 일부 웹사이트는 자동화된 접근을 감지하고 차단할 수 있습니다. 헤더 변경, 프록시 사용, 더 느린 스크롤 속도 조절 등을 고려해 볼 수 있습니다.
이 실습을 통해 여러분은 Playwright와 Python을 활용하여 복잡한 무한 스크롤 웹사이트의 데이터를 효과적으로 크롤링하는 강력한 기술을 습득했습니다. 이 지식을 바탕으로 다양한 동적 웹 환경에서 필요한 정보를 추출하고 분석하는 데 자유롭게 활용하시기 바랍니다.