Playwright는 현대 웹 애플리케이션의 복잡한 동적 콘텐츠를 다루는 데 최적화된 강력한 웹 자동화 라이브러리입니다. 기존의 정적 웹 스크래핑 도구로는 접근하기 어려웠던 JavaScript 기반의 동적 쇼핑몰 페이지에서 상품 데이터를 추출하고, 이를 분석 가능한 CSV 형태로 저장하는 것은 이제 더 이상 전문가만의 영역이 아닙니다. 본 강의를 통해 여러분은 단 5분 안에 기본적인 웹 스크래핑 파이프라인을 구축하고, 동적 웹 페이지의 데이터를 효과적으로 수집하는 방법을 완벽하게 마스터하게 될 것입니다.
학습 목표
본 튜토리얼을 통해 여러분은 다음의 학습 목표를 달성하게 됩니다.
- Playwright 라이브러리를 설치하고 기본적인 환경을 설정할 수 있습니다.
- 동적으로 로드되는 웹 페이지에 접속하고, 필요한 요소를 식별하는 방법을 이해합니다.
- Playwright를 사용하여 쇼핑몰의 상품명, 가격, 이미지 URL 등 핵심 데이터를 효율적으로 추출할 수 있습니다.
- 추출된 데이터를 Pandas DataFrame으로 가공하고, 표준 CSV 파일 형태로 저장할 수 있습니다.
- 실제 업무 환경에서 Playwright를 활용한 동적 웹 스크래핑의 기본기를 다질 수 있습니다.
사전 준비 사항
본 실습을 원활하게 진행하기 위해 다음 환경을 준비해 주시기 바랍니다. 이 과정은 여러분의 개발 환경에 따라 약간의 차이가 있을 수 있으나, 기본적인 설정은 동일합니다.
- 권장 IDE: Visual Studio Code (최신 버전)
- 운영체제: Windows 10/11, macOS (Ventura 이상), Linux (Ubuntu 20.04+ 등)
- Python 버전: 3.8 이상 (안정적인 실습을 위해 3.10 이상을 권장합니다.)
필수 라이브러리 설치
터미널 또는 명령 프롬프트를 열고 다음 명령어를 순서대로 실행하여 필요한 라이브러리와 Playwright 브라우저를 설치합니다.
bash
pip install playwright pandas
playwright install
위 명령어 중 `pip install playwright pandas`는 Playwright와 데이터 처리를 위한 Pandas 라이브러리를 설치합니다. 이어서 `playwright install` 명령어는 Playwright가 웹 페이지를 렌더링하는 데 필요한 Chromium, Firefox, WebKit 브라우저 바이너리를 자동으로 다운로드하여 설치합니다. 이 과정은 인터넷 환경에 따라 다소 시간이 소요될 수 있습니다.
단계별 실습 과정
이제 본격적으로 Playwright를 이용한 동적 쇼핑몰 상품 데이터 추출 및 CSV 저장 실습을 시작해 보겠습니다.
1단계: 프로젝트 초기 설정 및 Playwright 설치 확인
먼저, 실습을 위한 새로운 프로젝트 폴더를 생성하고, 해당 폴더 내에서 작업을 진행합니다. 예를 들어, `playwright_shop_scraper`라는 폴더를 생성하고 VS Code로 엽니다. 가상 환경을 설정하는 것은 좋은 습관이지만, 본 튜토리얼에서는 필수 사항은 아닙니다.
생성한 폴더 안에 `scraper.py` 파일을 만듭니다. Playwright가 제대로 설치되었는지 확인하기 위해 간단한 코드를 작성해 보겠습니다.
python
import asyncio
from playwright.async_api import async_playwright
async def check_playwright():
async with async_playwright() as p:
print(f”Playwright version: {p.version}”)
browser = await p.chromium.launch()
page = await browser.new_page()
await page.goto(“https://www.example.com”)
title = await page.title()
print(f”Page title: {title}”)
await browser.close()
if __name__ == “__main__”:
asyncio.run(check_playwright())
위 코드를 저장하고 터미널에서 `python scraper.py`를 실행하면, Playwright 버전과 ‘example.com’ 페이지의 제목이 출력되는 것을 확인할 수 있습니다. 이는 Playwright 환경이 성공적으로 설정되었음을 의미합니다.
2단계: Playwright를 이용한 웹 페이지 접속 및 동적 데이터 추출 전략 수립
동적 쇼핑몰 페이지는 JavaScript를 통해 상품 목록을 로드하므로, 페이지가 완전히 로드될 때까지 기다리는 것이 중요합니다. 여기서는 가상의 쇼핑몰 페이지(`https://example-dynamic-shop.com/products`)를 대상으로 한다고 가정하고, 이 페이지에서 상품 데이터를 추출하는 전략을 수립합니다.
가장 먼저 할 일은 `page.goto()` 메서드를 사용하여 원하는 URL로 이동하는 것입니다. 그리고 동적으로 로드되는 상품 목록이 나타날 때까지 `page.wait_for_selector()`를 사용하여 특정 HTML 요소(예: 상품 목록 컨테이너)가 나타날 때까지 기다려야 합니다. 이 과정은 웹 페이지의 로딩 속도나 콘텐츠 구성에 따라 매우 중요합니다.
웹 페이지의 요소를 식별하기 위해서는 웹 브라우저의 개발자 도구(F12)를 활용해야 합니다. 개발자 도구의 ‘요소(Elements)’ 탭에서 원하는 상품 정보(이름, 가격, 이미지)를 우클릭하여 ‘검사(Inspect)’를 선택하면 해당 요소의 HTML 구조를 확인할 수 있습니다. 이때 CSS 선택자(CSS Selector)를 정확하게 찾아내는 것이 핵심입니다. 예를 들어, 모든 상품 카드가 `
`, 가격은 ``, 이미지 URL은 `![]() `에 있다면, 이 선택자들을 활용하여 데이터를 추출할 수 있습니다.
`에 있다면, 이 선택자들을 활용하여 데이터를 추출할 수 있습니다.
3단계: 상품 정보 추출을 위한 Playwright 코드 작성
이제 본격적으로 쇼핑몰 페이지에서 상품 정보를 추출하는 코드를 작성합니다. `scraper.py` 파일의 내용을 다음과 같이 수정합니다.
python
import asyncio
import pandas as pd
from playwright.async_api import async_playwright
async def scrape_shop_products():
products_data = []
async with async_playwright() as p:
# Headless 모드 (브라우저 GUI 없이 실행) 비활성화하여 동작 확인 (개발 시 유용)
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
# 가상의 동적 쇼핑몰 URL (실제 작동하는 URL로 대체해야 합니다)
# 예시: https://www.coupang.com 또는 https://www.gmarket.co.kr 등 실제 쇼핑몰 페이지의 상품 목록 URL
target_url = “https://playwright.dev/” # 예시를 위해 Playwright 공식 문서 사용. 실제 쇼핑몰 URL로 변경하세요.
await page.goto(target_url, wait_until=”domcontentloaded”) # DOMContentLoaded 이벤트 발생까지 대기
# 동적 콘텐츠 로드를 위한 대기 (실제 쇼핑몰에서는 상품 목록 컨테이너의 CSS 선택자로 변경)
# 예: await page.wait_for_selector(“.product-list-container”, timeout=10000)
# 여기서는 예시로 body 태그가 로드될 때까지 기다립니다.
await page.wait_for_selector(“body”, timeout=10000)
# 가상의 상품 카드 선택자 (실제 쇼핑몰의 상품 카드 선택자로 변경 필요)
# 예: product_cards = await page.locator(“.product-card”).all()
# Playwright 공식 문서에서 특정 섹션의 링크들을 상품으로 가정하여 추출합니다.
product_cards = await page.locator(“nav.navbar >> a”).all() # 예시: Playwright docs 상단 메뉴 링크
print(f”총 {len(product_cards)}개의 상품(링크) 발견.”)
for i, card in enumerate(product_cards):
try:
# 가상의 상품명, 가격, 이미지 URL 추출 (실제 쇼핑몰 선택자로 변경 필요)
# 예: title = await card.locator(“.product-title”).text_content()
# 예: price = await card.locator(“.product-price”).text_content()
# 예: image_url = await card.locator(“.product-image”).get_attribute(“src”)
title = await card.text_content() # 링크 텍스트를 상품명으로 가정
link = await card.get_attribute(“href”) # 링크 URL을 상품 상세 페이지로 가정
price = “N/A” # 예시이므로 가격은 N/A로 설정
image_url = “N/A” # 예시이므로 이미지 URL은 N/A로 설정
if title and link:
products_data.append({
“상품명”: title.strip(),
“가격”: price.strip() if price != “N/A” else price,
“링크”: link.strip(),
“이미지_URL”: image_url.strip() if image_url != “N/A” else image_url
})
except Exception as e:
print(f”상품 카드 {i} 추출 중 오류 발생: {e}”)
continue
await browser.close()
return products_data
if __name__ == “__main__”:
# 실제 쇼핑몰 URL과 선택자로 변경하여 사용하세요!
print(“Playwright로 동적 쇼핑몰 상품 데이터 추출 시작…”)
scraped_data = asyncio.run(scrape_shop_products())
print(“데이터 추출 완료.”)
# 다음 단계에서 이 데이터를 CSV로 저장합니다.
코드 설명:
* `async_playwright()`: Playwright 인스턴스를 비동기적으로 관리합니다.
* `browser = await p.chromium.launch(headless=False)`: Chromium 브라우저를 실행합니다. `headless=False`는 브라우저 GUI를 띄워 스크래핑 과정을 눈으로 확인할 수 있게 해줍니다. 실제 배포 시에는 `True`로 설정하여 백그라운드에서 실행하는 것이 효율적입니다.
* `await page.goto(target_url, wait_until=”domcontentloaded”)`: 지정된 URL로 이동하고, DOM 콘텐츠가 로드될 때까지 기다립니다. `networkidle` 등 다른 `wait_until` 옵션도 활용할 수 있습니다.
* `await page.wait_for_selector(“body”, timeout=10000)`: 특정 CSS 선택자를 가진 요소가 페이지에 나타날 때까지 최대 10초(10000ms) 동안 기다립니다. 동적 콘텐츠 로딩에 필수적인 부분입니다. 실제 쇼핑몰에서는 상품 목록을 감싸는 컨테이너의 선택자를 사용해야 합니다.
* `product_cards = await page.locator(“nav.navbar >> a”).all()`: CSS 선택자를 사용하여 페이지 내의 모든 상품 카드 요소를 찾습니다. `locator()`는 Playwright의 강력한 선택자로, 여러 요소를 효율적으로 다룰 수 있게 해줍니다. `.all()`을 통해 모든 일치하는 요소를 리스트로 가져옵니다.
* `for card in product_cards:`: 추출된 각 상품 카드 요소에 대해 반복문을 실행합니다.
* `await card.locator(“.product-title”).text_content()`: 각 상품 카드 내에서 상품명, 가격, 이미지 URL 등 세부 정보를 CSS 선택자를 이용해 추출합니다. `text_content()`는 요소의 텍스트 내용을, `get_attribute(“src”)`는 `src` 속성 값을 가져옵니다.
* `products_data.append({…})`: 추출된 데이터를 딕셔너리 형태로 리스트에 추가합니다.
4단계: 추출된 데이터를 CSV 파일로 저장
이제 마지막 단계로, 추출된 `products_data` 리스트를 Pandas DataFrame으로 변환하고, 이를 CSV 파일로 저장합니다. `scraper.py` 파일의 `if __name__ == “__main__”:` 블록을 다음과 같이 수정합니다.
python
# … (이전 코드 동일)
if __name__ == “__main__”:
print(“Playwright로 동적 쇼핑몰 상품 데이터 추출 시작…”)
scraped_data = asyncio.run(scrape_shop_products())
print(f”총 {len(scraped_data)}개의 상품 데이터를 성공적으로 추출했습니다.”)
if scraped_data:
# Pandas DataFrame으로 변환
df = pd.DataFrame(scraped_data)
# CSV 파일로 저장 (한글 깨짐 방지를 위해 ‘utf-8-sig’ 인코딩 사용)
output_filename = “shop_products.csv”
df.to_csv(output_filename, index=False, encoding=’utf-8-sig’)
print(f”추출된 데이터가 ‘{output_filename}’ 파일로 성공적으로 저장되었습니다.”)
else:
print(“추출된 데이터가 없습니다. 스크래핑 설정 또는 대상 페이지를 확인하세요.”)
코드 설명:
* `import pandas as pd`: Pandas 라이브러리를 임포트합니다.
* `df = pd.DataFrame(scraped_data)`: 추출된 딕셔너리 리스트를 Pandas DataFrame 객체로 변환합니다. DataFrame은 표 형태의 데이터를 다루는 데 매우 유용합니다.
* `df.to_csv(output_filename, index=False, encoding=’utf-8-sig’)`: DataFrame을 CSV 파일로 저장합니다.
* `output_filename`: 저장할 파일의 이름입니다.
* `index=False`: DataFrame의 기본 인덱스를 CSV 파일에 포함하지 않도록 합니다.
* `encoding=’utf-8-sig’`: 한글 텍스트가 포함된 경우 CSV 파일이 Microsoft Excel 등에서 열었을 때 깨지지 않도록 ‘UTF-8 with BOM’ 형식으로 인코딩합니다. 이는 한국어 환경에서 매우 중요한 설정입니다.
결과 확인
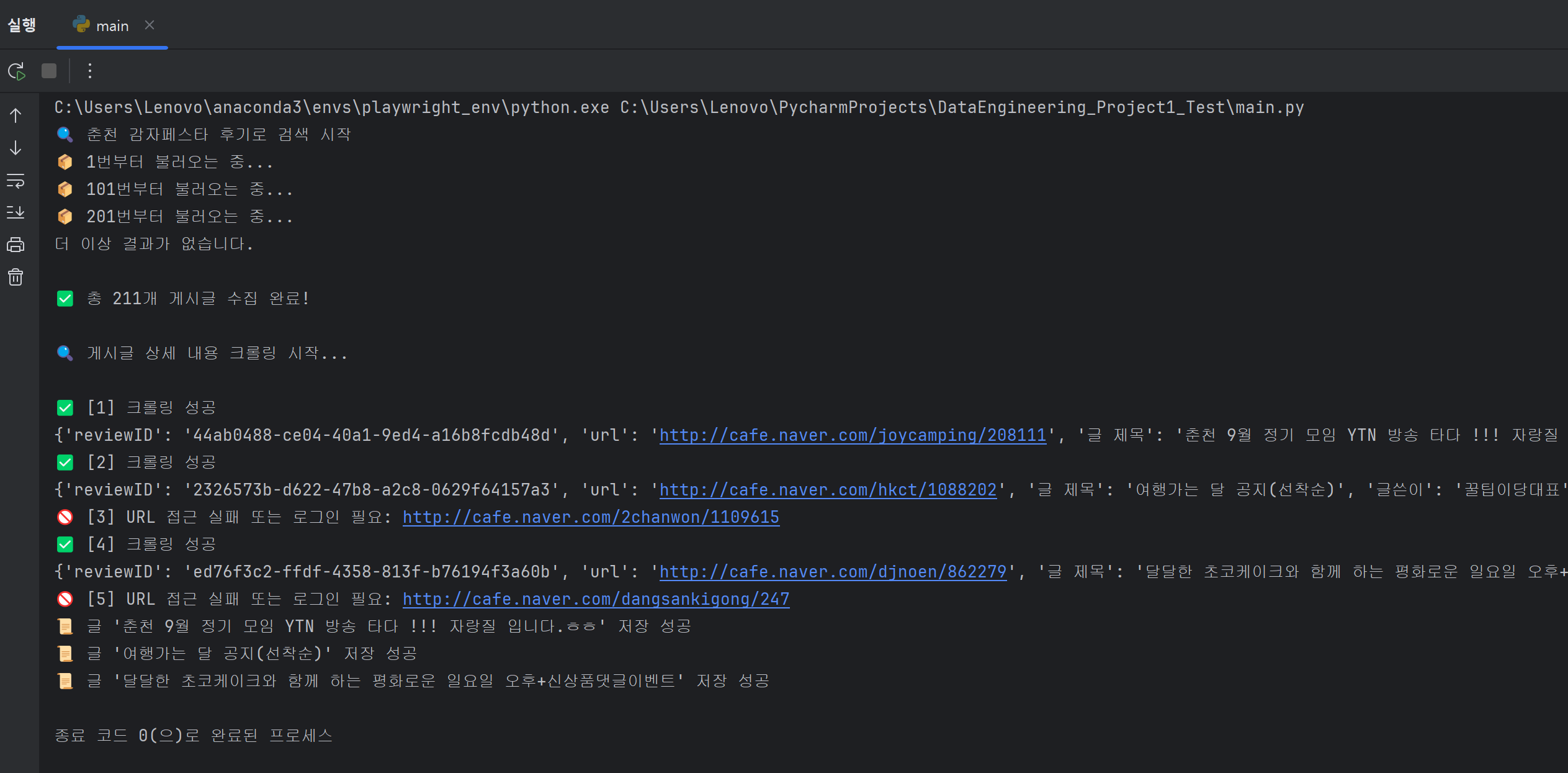
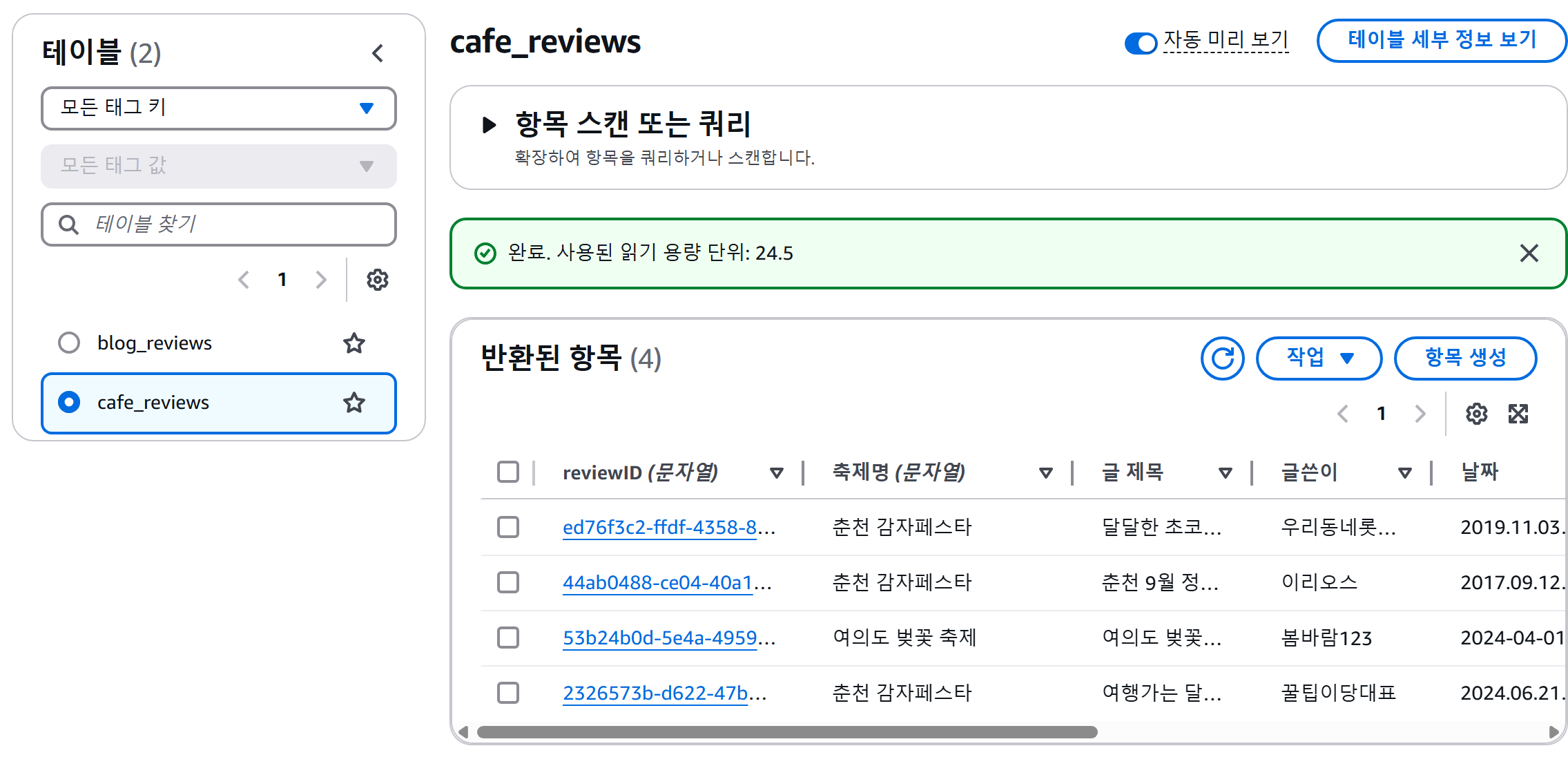
모든 코드를 작성하고 `python scraper.py` 명령어를 다시 실행하면, Playwright가 브라우저를 실행하고 지정된 쇼핑몰 페이지에서 데이터를 추출한 후, 프로젝트 폴더 내에 `shop_products.csv` 파일이 생성될 것입니다.
생성된 `shop_products.csv` 파일을 엑셀이나 다른 CSV 뷰어로 열어보면, ‘상품명’, ‘가격’, ‘링크’, ‘이미지_URL’ 등의 열에 추출된 쇼핑몰 상품 데이터가 깔끔하게 정리되어 있는 것을 확인할 수 있습니다. 만약 데이터가 예상과 다르게 추출되었거나 오류가 발생했다면, 2단계에서 언급된 개발자 도구를 활용하여 CSS 선택자가 정확한지, `wait_for_selector` 대기 시간이 충분한지 등을 다시 한번 확인해 보시기 바랍니다.
이 튜토리얼을 통해 여러분은 Playwright를 사용하여 동적 웹 페이지에서 데이터를 추출하고, 이를 분석 가능한 형태로 저장하는 실질적인 기술을 습득했습니다. 이제 이 지식을 바탕으로 다양한 웹 스크래핑 프로젝트에 도전하고, 더 복잡한 시나리오(예: 페이지네이션 처리, 로그인 필요 페이지, 무한 스크롤 등)에도 Playwright를 적용해 볼 수 있을 것입니다. Playwright의 강력함과 유연성을 직접 경험하며 여러분의 IT 실무 역량을 한 단계 더 끌어올리세요!

import asyncio
import pandas as pd
from playwright.async_api import async_playwright
products_data = []
async with async_playwright() as p:
# Headless 모드 (브라우저 GUI 없이 실행) 비활성화하여 동작 확인 (개발 시 유용)
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
# 예시: https://www.coupang.com 또는 https://www.gmarket.co.kr 등 실제 쇼핑몰 페이지의 상품 목록 URL
target_url = “https://playwright.dev/” # 예시를 위해 Playwright 공식 문서 사용. 실제 쇼핑몰 URL로 변경하세요.
await page.goto(target_url, wait_until=”domcontentloaded”) # DOMContentLoaded 이벤트 발생까지 대기
# 예: await page.wait_for_selector(“.product-list-container”, timeout=10000)
# 여기서는 예시로 body 태그가 로드될 때까지 기다립니다.
await page.wait_for_selector(“body”, timeout=10000)
# 예: product_cards = await page.locator(“.product-card”).all()
# Playwright 공식 문서에서 특정 섹션의 링크들을 상품으로 가정하여 추출합니다.
product_cards = await page.locator(“nav.navbar >> a”).all() # 예시: Playwright docs 상단 메뉴 링크
try:
# 가상의 상품명, 가격, 이미지 URL 추출 (실제 쇼핑몰 선택자로 변경 필요)
# 예: title = await card.locator(“.product-title”).text_content()
# 예: price = await card.locator(“.product-price”).text_content()
# 예: image_url = await card.locator(“.product-image”).get_attribute(“src”)
link = await card.get_attribute(“href”) # 링크 URL을 상품 상세 페이지로 가정
price = “N/A” # 예시이므로 가격은 N/A로 설정
image_url = “N/A” # 예시이므로 이미지 URL은 N/A로 설정
products_data.append({
“상품명”: title.strip(),
“가격”: price.strip() if price != “N/A” else price,
“링크”: link.strip(),
“이미지_URL”: image_url.strip() if image_url != “N/A” else image_url
})
except Exception as e:
print(f”상품 카드 {i} 추출 중 오류 발생: {e}”)
continue
return products_data
# 실제 쇼핑몰 URL과 선택자로 변경하여 사용하세요!
print(“Playwright로 동적 쇼핑몰 상품 데이터 추출 시작…”)
scraped_data = asyncio.run(scrape_shop_products())
print(“데이터 추출 완료.”)
# 다음 단계에서 이 데이터를 CSV로 저장합니다.
* `browser = await p.chromium.launch(headless=False)`: Chromium 브라우저를 실행합니다. `headless=False`는 브라우저 GUI를 띄워 스크래핑 과정을 눈으로 확인할 수 있게 해줍니다. 실제 배포 시에는 `True`로 설정하여 백그라운드에서 실행하는 것이 효율적입니다.
* `await page.goto(target_url, wait_until=”domcontentloaded”)`: 지정된 URL로 이동하고, DOM 콘텐츠가 로드될 때까지 기다립니다. `networkidle` 등 다른 `wait_until` 옵션도 활용할 수 있습니다.
* `await page.wait_for_selector(“body”, timeout=10000)`: 특정 CSS 선택자를 가진 요소가 페이지에 나타날 때까지 최대 10초(10000ms) 동안 기다립니다. 동적 콘텐츠 로딩에 필수적인 부분입니다. 실제 쇼핑몰에서는 상품 목록을 감싸는 컨테이너의 선택자를 사용해야 합니다.
* `product_cards = await page.locator(“nav.navbar >> a”).all()`: CSS 선택자를 사용하여 페이지 내의 모든 상품 카드 요소를 찾습니다. `locator()`는 Playwright의 강력한 선택자로, 여러 요소를 효율적으로 다룰 수 있게 해줍니다. `.all()`을 통해 모든 일치하는 요소를 리스트로 가져옵니다.
* `for card in product_cards:`: 추출된 각 상품 카드 요소에 대해 반복문을 실행합니다.
* `await card.locator(“.product-title”).text_content()`: 각 상품 카드 내에서 상품명, 가격, 이미지 URL 등 세부 정보를 CSS 선택자를 이용해 추출합니다. `text_content()`는 요소의 텍스트 내용을, `get_attribute(“src”)`는 `src` 속성 값을 가져옵니다.
* `products_data.append({…})`: 추출된 데이터를 딕셔너리 형태로 리스트에 추가합니다.
# … (이전 코드 동일)
print(“Playwright로 동적 쇼핑몰 상품 데이터 추출 시작…”)
scraped_data = asyncio.run(scrape_shop_products())
print(f”총 {len(scraped_data)}개의 상품 데이터를 성공적으로 추출했습니다.”)
# Pandas DataFrame으로 변환
df = pd.DataFrame(scraped_data)
output_filename = “shop_products.csv”
df.to_csv(output_filename, index=False, encoding=’utf-8-sig’)
print(f”추출된 데이터가 ‘{output_filename}’ 파일로 성공적으로 저장되었습니다.”)
else:
print(“추출된 데이터가 없습니다. 스크래핑 설정 또는 대상 페이지를 확인하세요.”)
* `df = pd.DataFrame(scraped_data)`: 추출된 딕셔너리 리스트를 Pandas DataFrame 객체로 변환합니다. DataFrame은 표 형태의 데이터를 다루는 데 매우 유용합니다.
* `df.to_csv(output_filename, index=False, encoding=’utf-8-sig’)`: DataFrame을 CSV 파일로 저장합니다.
* `output_filename`: 저장할 파일의 이름입니다.
* `index=False`: DataFrame의 기본 인덱스를 CSV 파일에 포함하지 않도록 합니다.
* `encoding=’utf-8-sig’`: 한글 텍스트가 포함된 경우 CSV 파일이 Microsoft Excel 등에서 열었을 때 깨지지 않도록 ‘UTF-8 with BOM’ 형식으로 인코딩합니다. 이는 한국어 환경에서 매우 중요한 설정입니다.