학습 목표
본 실전 가이드를 통해 여러분은 Python Playwright 라이브러리를 사용하여 JavaScript로 동적으로 로드되는 웹사이트의 데이터를 효과적으로 추출하는 방법을 완벽하게 마스터하게 될 것입니다. 기존의 정적 웹 크롤링 방식으로는 접근하기 어려웠던 로그인, 버튼 클릭, 스크롤링 등 사용자 인터랙션이 필요한 복잡한 시나리오에서도 원하는 정보를 정확하게 수집하고 처리하는 실무 역량을 갖추게 됩니다.
구체적으로, 다음 내용을 학습합니다:
- Playwright 환경 설정 및 기본 동작 이해
- 동적 웹사이트의 JavaScript 콘텐츠 로딩 메커니즘 분석
- Playwright의 비동기 기능(
wait_for_selector,wait_for_load_state등)을 활용한 동적 콘텐츠 대기 및 추출 - 추출된 데이터의 파싱 및 체계적인 저장 (CSV 또는 JSON 형식)
- 실제 웹 크롤링 프로젝트에 Playwright를 적용하기 위한 실용적인 팁과 베스트 프랙티스
사전 준비 사항
본 실습은 다음과 같은 환경에서 진행하는 것을 권장합니다. 안정적인 실습을 위해 아래 명시된 환경을 구축해 주시기 바랍니다.
- 권장 IDE: Visual Studio Code (VS Code)
- 운영체제(OS): Windows 10/11, macOS (Intel/Apple Silicon), Linux (Ubuntu 20.04+ 등) – Playwright는 주요 운영체제를 모두 지원합니다.
- Python 버전: Python 3.8 이상 (권장: Python 3.10 이상)
필수 라이브러리 설치는 터미널 또는 명령 프롬프트에서 다음 명령어를 실행하여 진행합니다:
pip install playwright beautifulsoup4 pandas
playwright install위 명령어는 Playwright 라이브러리와 함께 웹 페이지 파싱을 위한 Beautiful Soup 4, 그리고 데이터 처리를 위한 Pandas 라이브러리를 설치합니다. playwright install 명령어는 Chromium, Firefox, WebKit과 같은 브라우저 드라이버를 자동으로 다운로드하여 Playwright가 웹 브라우저를 제어할 수 있도록 준비합니다.
단계별 실습 과정
1단계: Playwright 설치 및 기본 브라우저 제어
Playwright를 사용하기 위한 초기 설정은 매우 간단합니다. 앞서 pip install playwright 및 playwright install 명령어를 통해 필요한 모든 구성 요소가 설치되었습니다. 이제 간단한 스크립트를 작성하여 Playwright가 브라우저를 성공적으로 제어하는지 확인해 봅시다.
다음 코드를 basic_playwright.py 파일로 저장하고 실행해 보세요.
import asyncio
from playwright.async_api import sync_playwright
async def run():
async with sync_playwright() as p:
# Chromium 브라우저 실행 (headless=False는 브라우저 창을 띄웁니다)
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
# 구글 웹사이트로 이동
print("Google 웹사이트로 이동 중...")
await page.goto("https://www.google.com")
print("현재 페이지 제목:", await page.title())
# 3초 대기 후 브라우저 닫기
await page.wait_for_timeout(3000)
await browser.close()
print("브라우저 종료.")
if __name__ == "__main__":
asyncio.run(run())
터미널에서 이 스크립트를 실행하면 Chromium 브라우저가 열리고 Google 웹사이트로 이동한 다음, 잠시 후 자동으로 닫히는 것을 확인할 수 있습니다.
python basic_playwright.py2단계: 동적 웹사이트 구조 분석 및 JavaScript 콘텐츠 식별
동적 웹사이트는 초기 HTML 로드 후 JavaScript를 통해 추가 콘텐츠를 가져오거나 페이지를 변경합니다. 이러한 콘텐츠는 requests 라이브러리와 같은 정적 HTTP 요청 방식으로는 접근하기 어렵습니다. Playwright를 사용하기 전에 크롤링하고자 하는 웹사이트의 동적 요소를 식별하는 것이 중요합니다.
크롬(Chrome) 또는 엣지(Edge) 브라우저의 개발자 도구 (Developer Tools)를 활용하세요. F12 키를 눌러 개발자 도구를 열고 다음 탭을 주로 확인합니다:
- Elements 탭: 페이지의 현재 렌더링된 HTML 구조를 실시간으로 보여줍니다. JavaScript에 의해 변경되거나 추가된 요소를 여기서 확인할 수 있습니다.
- Network 탭: 웹사이트가 로드되는 동안 주고받는 모든 네트워크 요청을 보여줍니다. XHR/Fetch 요청을 필터링하여 JavaScript가 비동기적으로 데이터를 가져오는 API 호출을 식별할 수 있습니다.
예를 들어, 특정 게시판 페이지에서 ‘더 보기’ 버튼을 클릭했을 때 새로운 게시글이 로드된다면, 해당 버튼의 클릭 이벤트가 JavaScript를 통해 새로운 데이터를 서버에서 가져와 DOM에 추가하는 방식일 가능성이 높습니다. 우리는 Playwright를 사용하여 이러한 ‘더 보기’ 버튼을 클릭하고, 새로운 콘텐츠가 나타날 때까지 기다린 후 데이터를 추출할 것입니다.
3단계: Playwright로 JavaScript 콘텐츠 대기 및 추출
이제 Playwright의 핵심 기능 중 하나인 동적 콘텐츠 대기 및 추출 방법을 실습합니다. 우리는 가상의 동적 웹페이지를 대상으로, JavaScript 로딩 후 나타나는 특정 요소를 추출하는 시나리오를 구현해 보겠습니다. 실제 웹사이트에서는 로딩 스피너가 사라지거나, 특정 데이터 목록이 나타나는 등의 변화를 관찰하게 됩니다.
다음 코드는 특정 URL로 이동한 후, JavaScript에 의해 약 5초 후에 나타나는 가상의 ‘동적 콘텐츠’를 기다린 다음 해당 텍스트를 추출하는 예제입니다. 실제 웹사이트에서는 wait_for_selector를 사용하여 특정 CSS 선택자가 나타날 때까지 기다리는 것이 일반적입니다.
dynamic_scraper.py 파일로 저장하고 실행해 보세요.
import asyncio
from playwright.async_api import sync_playwright
async def scrape_dynamic_content():
async with sync_playwright() as p:
browser = await p.chromium.launch(headless=True) # headless=True로 브라우저 창 없이 실행
page = await browser.new_page()
# 가상의 동적 콘텐츠를 포함하는 페이지로 이동 (예시: JavaScript로 5초 후 div 추가)
# 실제 웹사이트 URL을 여기에 입력하세요.
# 이 예시를 위해 간단한 로컬 HTML 파일을 만들거나, JS로 동적 콘텐츠를 로드하는 페이지를 상정합니다.
# 여기서는 편의상 Playwright가 페이지 로드 후 5초를 기다리게 합니다. (실제는 wait_for_selector 사용)
print("동적 콘텐츠 페이지로 이동 중...")
await page.goto("https://www.example.com") # 실제 동적 페이지 URL로 변경 필요
# 개발자 도구에서 확인한 동적 콘텐츠의 CSS 선택자를 사용합니다.
# 예를 들어, JavaScript로 'dynamic-data'라는 클래스를 가진 div가 로드된다고 가정합니다.
dynamic_selector = ".dynamic-data"
print(f"'{dynamic_selector}' 선택자가 나타날 때까지 대기 중...")
try:
# 요소가 나타날 때까지 최대 10초 대기
await page.wait_for_selector(dynamic_selector, timeout=10000)
print("동적 콘텐츠 선택자 발견!")
# 동적 콘텐츠 텍스트 추출
element_text = await page.locator(dynamic_selector).inner_text()
print("추출된 동적 콘텐츠:", element_text)
# 더 복잡한 데이터 추출 (예: 여러 항목)
# all_items = await page.locator(".item-list .item").all_inner_texts()
# print("모든 항목:", all_items)
except Exception as e:
print(f"동적 콘텐츠 로드 실패 또는 타임아웃: {e}")
await browser.close()
print("브라우저 종료.")
if __name__ == "__main__":
asyncio.run(scrape_dynamic_content())
참고: 위 코드에서 https://www.example.com은 예시 URL입니다. 실제 동적 콘텐츠가 로드되는 웹사이트의 URL과 해당 콘텐츠의 정확한 CSS 선택자(예: .dynamic-data)를 찾아 변경해야 합니다. page.wait_for_selector()는 특정 요소가 DOM에 나타날 때까지 기다리므로, JavaScript에 의해 뒤늦게 생성되는 콘텐츠를 안정적으로 포착할 수 있습니다.
4단계: 추출된 데이터 처리 및 저장
Playwright를 통해 동적으로 로드된 HTML 콘텐츠를 성공적으로 추출했다면, 이제 이 데이터를 구조화하고 저장하는 과정이 필요합니다. Beautiful Soup 4 라이브러리는 HTML 파싱에 매우 유용하며, Pandas는 데이터를 표 형태로 관리하고 CSV, JSON 등으로 저장하는 데 강력합니다.
이전 단계에서 추출한 element_text가 단일 텍스트였다면, 실제 시나리오에서는 여러 개의 데이터 항목(예: 제품명, 가격, 설명)을 추출하게 될 것입니다. 다음은 Playwright로 전체 페이지의 HTML을 가져와 Beautiful Soup으로 파싱하고, 데이터를 Pandas DataFrame으로 만든 후 CSV 파일로 저장하는 예시입니다.
data_processor.py 파일로 저장하고 실행해 보세요.
import asyncio
import pandas as pd
from bs4 import BeautifulSoup
from playwright.async_api import sync_playwright
async def process_and_save_data():
async with sync_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
target_url = "https://quotes.toscrape.com/js/" # JavaScript로 동적 로딩되는 예시 페이지
print(f"{target_url} 페이지로 이동 중...")
await page.goto(target_url)
# JavaScript 콘텐츠가 완전히 로드될 때까지 대기
# 이 페이지는 모든 인용구가 로드된 후 특정 footer가 나타납니다.
await page.wait_for_selector(".footer")
print("페이지 로드 완료 및 동적 콘텐츠 대기 완료.")
# 렌더링된 전체 HTML 콘텐츠 가져오기
html_content = await page.content()
await browser.close()
print("브라우저 종료.")
# Beautiful Soup으로 HTML 파싱
soup = BeautifulSoup(html_content, 'html.parser')
quotes_data = []
# 각 인용구(quote) 요소 찾기
for quote_div in soup.select('div.quote'):
text = quote_div.find('span', class_='text').get_text(strip=True)
author = quote_div.find('small', class_='author').get_text(strip=True)
tags = [tag.get_text(strip=True) for tag in quote_div.find('div', class_='tags').find_all('a', class_='tag')]
quotes_data.append({
'text': text,
'author': author,
'tags': ', '.join(tags) # 태그는 콤마로 구분된 문자열로 저장
})
# Pandas DataFrame으로 변환
df = pd.DataFrame(quotes_data)
# 데이터를 CSV 파일로 저장
output_filename = "quotes_data.csv"
df.to_csv(output_filename, index=False, encoding='utf-8-sig')
print(f"데이터가 '{output_filename}' 파일로 성공적으로 저장되었습니다.")
if __name__ == "__main__":
asyncio.run(process_and_save_data())
이 코드는 quotes.toscrape.com/js/와 같이 JavaScript로 콘텐츠가 동적으로 로드되는 실제 예시 페이지를 사용합니다. page.content()로 가져온 HTML은 JavaScript에 의해 완전히 렌더링된 상태이므로, Beautiful Soup이 이를 파싱하여 원하는 데이터를 추출할 수 있습니다. 추출된 데이터는 Pandas DataFrame을 거쳐 CSV 파일로 저장됩니다.
결과 확인
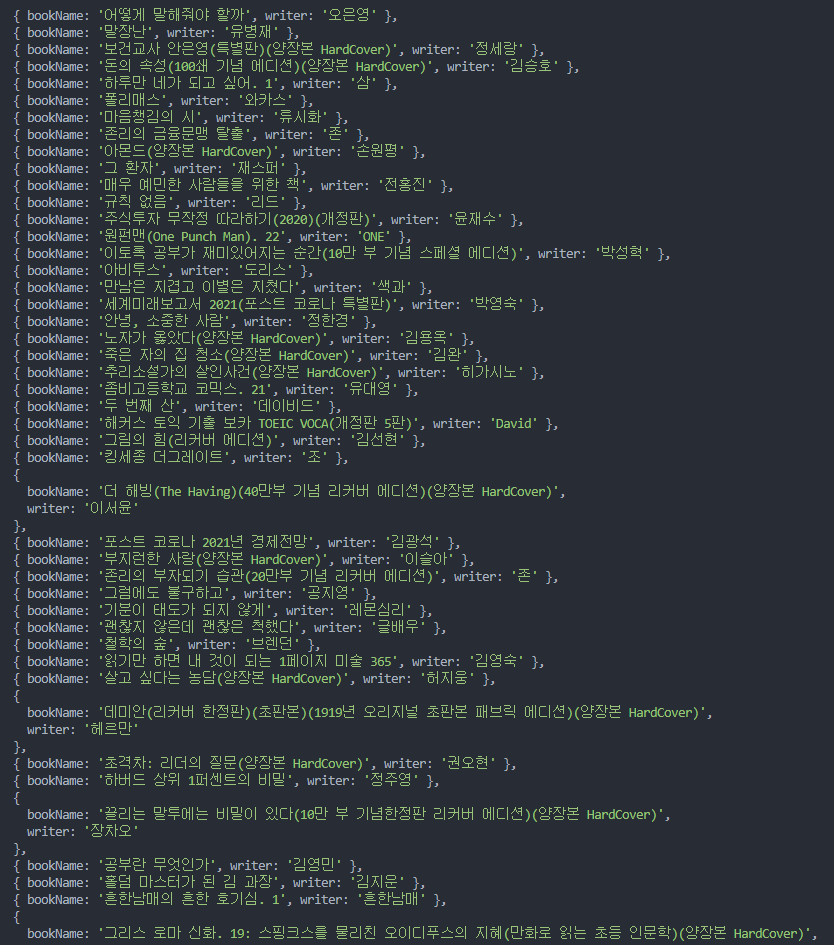
위 data_processor.py 스크립트를 성공적으로 실행했다면, 스크립트가 실행된 동일한 디렉토리에 quotes_data.csv 파일이 생성되었을 것입니다. 이 파일을 텍스트 편집기나 스프레드시트 프로그램(예: Microsoft Excel, Google Sheets)으로 열어보면, 웹페이지에서 추출된 인용구, 저자, 태그 정보가 깔끔하게 정리되어 있는 것을 확인할 수 있습니다.
예시 quotes_data.csv 내용:
text,author,tags
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”,Albert Einstein,change,deep-thoughts,thinking,world
“It is our choices, Harry, that show what we truly are, far more than our abilities.”,J.K. Rowling,abilities,choices
... (더 많은 데이터)
만약 파일이 생성되지 않거나 내용이 비어있다면, 다음 사항을 확인해 보세요:
- 스크립트 실행 중 오류 메시지가 있었는지 확인합니다. (터미널 출력)
- 크롤링 대상 웹사이트의 URL이 올바른지, 그리고 CSS 선택자(
.quote,.text등)가 변경되지 않았는지 개발자 도구를 통해 다시 확인합니다. page.wait_for_selector()의 타임아웃이 너무 짧지는 않았는지 확인합니다. 웹사이트의 로딩 속도에 따라 충분한 시간을 주어야 합니다.
마무리
축하합니다! 여러분은 Python Playwright를 활용하여 동적 웹사이트의 JavaScript 콘텐츠를 성공적으로 추출하고 데이터를 처리하는 방법을 익혔습니다. 이제 여러분은 단순히 정적인 HTML만을 긁어오는 것을 넘어, 사용자 인터랙션이 필요한 복잡한 웹 페이지에서도 필요한 정보를 안정적으로 수집할 수 있는 강력한 도구를 손에 넣었습니다.
이 기술은 주식 데이터, 부동산 정보, 뉴스 기사, 이커머스 제품 정보 등 다양한 분야에서 가치 있는 데이터를 수집하는 데 활용될 수 있습니다. Playwright는 단순히 데이터 추출뿐만 아니라 웹 자동화, 테스트 등 광범위한 영역에서 활용될 수 있으므로, 앞으로 더 깊이 탐구해 보시길 권장합니다. 끊임없이 변화하는 웹 환경에서 이 강력한 도구를 통해 여러분의 데이터 수집 및 자동화 역량을 한 단계 더 발전시키시길 바랍니다.